写入过程-索引在内存的数据结构
有人可能会问,在索引持久化那章中不是有说索引在内存中用map存储,什么时候刷盘呢?
其实 ==索引文件在内存中对应的状态,索引文件在内存中有保存有多少数据,每个文件里的索引的消息对应什么状态等==.
而本章说的是消息的实体内容怎么保存在内存里,当消费者来消费数据的时候,消费者去哪个内存块拿数据.
RabbitMQ的消息在客户端指定了消息需要持久化的情况下每次写入,至少会往内核里写一次写数据.如果==消息是非持久化,但是消息过多,内存紧张的情况下,RabbitMQ也会强制将消息进行将数据刷到磁盘==。
但是唯一不同的就是 ==持久化数据在服务重启的时候,数据会进行恢复,数据还可以继续消费.但是非持久化的数据在服务器重启的时候,会自动的被丢弃掉==.
磁盘只是帮我们存储数据的,但是如果我们生产很快,消费很慢数据落盘了,我们咋去消费数据呢?怎么从磁盘中读取?
有人会问队列不是有序的吗?在索引持久化章中不是说过索引都是追加的形式写到磁盘的吗?那我们消费从头到尾去读取文件就行了呀.
从头到尾肯定是没错的.但这有几个其他细节。
比如消息有可能一部分是持久化,一部分是非持化的. ,那我们只读取索引文件就不行了.并且即使能实现,那消费和写入的性能怎么达到平衡呢?
RabbitMQ开发者为了这个他们也是绞尽脑汁的。
==把一个消息转成有多个状态,在索引和消息都在内存,索引在内存消息在磁盘,索引和消息都在磁盘 等几个状态. 把不同的状态的消息放在不同的List 里. 然后在不同情况下数据进行转移.==
这些逻辑关系可能是RabbitMQ模块中最为复杂逻辑之一了.下面我们就来缕缕.
==每个队列进程里都有 Q1,Q2,Q3,Q4 四个List==.
这些List就是我们语言开发里常说的队列. 但这个队列不是我们说的RabbitMQ的队列.这个概念要分清楚来.
消息有几个状态 ,但并不是所有消息都会经过下面几个状态,这只是在内存不够的情况下为了优化性rabbitmq开发者们把消息转面的抽象状态概念
apaha: 索引和数据全在内存
beta: 索引在内存,数据在磁盘
delta: 索引和数据都在磁盘
==Q1,和Q4 两个list里的消息都是apaha状态==
==Q2,和 Q3 都是beta状态==
list 数据流过程过程如下
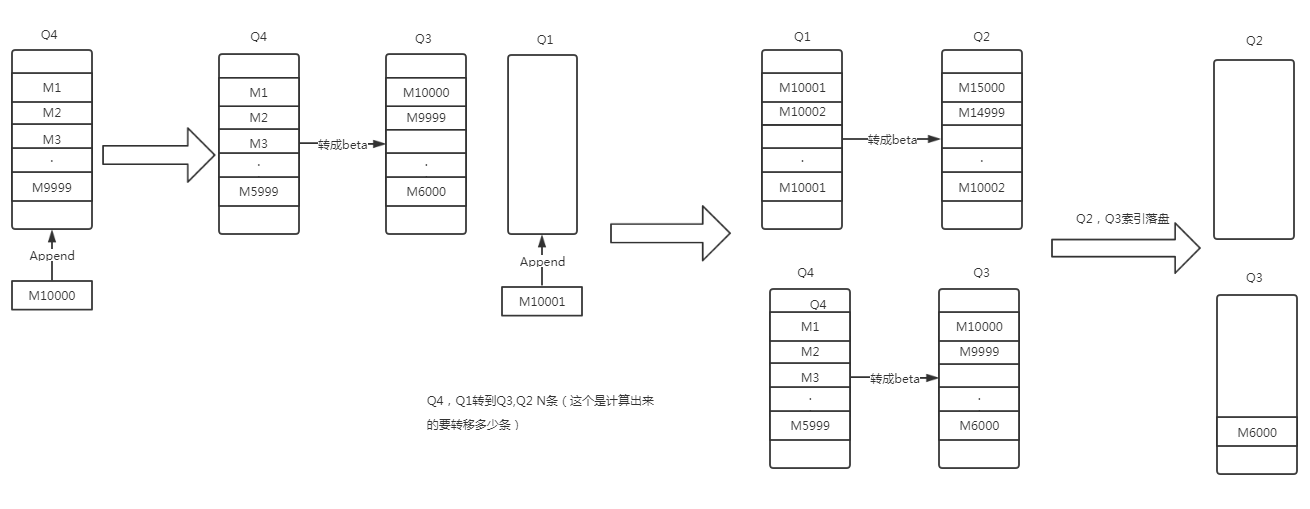
1. 假如写入的时候Q3里没有数据,那写数据写入到Q4
这个很好理解。并且消费的时候,这个时候肯定 是从Q4里拿数据,没有什么疑问。
1.1 将Q4数据写入到Q3的情况
每次操作完都会进行一次判断当前内存条数总数 ==>== 当前进程里的参数target_ram_count。 target_ram_count 这个参数请参考 内存监控章节。
内存总条数包括已经分配给了消费者待ack的数量
超过最大条数阈值 Quota= target_ram_count - ramTotal
将Q4末尾的Quota 条数据数据读并且写入磁盘(假如这条数据是非持久化的情况下,如果是持久化的数据就不再写入磁盘,因为已经写入过了)。
这个写入只会将 ==消息大小 > 参数:queue_index_embed_msgs_below== 的值消息内容写到磁盘,==索引信息并不会刷盘,只保留索引信息在内存==。
接着就将这消息写到Q3的头部,Q3是越在头部的信息,数据越晚,。和Q4是反过来的。
1.2 将Q3的数据一部分从内存中清除。
上面只是把Q4里的Quota条消息转到了Q3,但是内存的消息条数并没有改变。
所以在这个一步里,==将Q3里的数据Quota 条数据从Q3里清除,但不管如何都会保留最开头的那条消息,也就是Q3末尾的那一条==。
因为Q3里最末尾的数据是最早的数据。这里要保底最早的数据,因为在消费Q4的数据消费完了,就再从Q3里开始消费。
当Q3里只有一条消息的时候,会再从磁盘中读取一批出来。
2. 写入的时候Q3有数据
假如写入的时候Q3里有数据,那就将数据写入到Q1. 这时候走去判断内存条数 与 target_ram_count 的大小,就有点复杂了。
因为这个时候,Q1,Q3 肯定都有数据,Q2,和Q4也很有可能也有数据。
超过最大条数阈值 Quota= ramTotal - target_ram_count
2.1 将Q1的Quota 条数据转移到Q2
方法和Q4转移到Q3一样。
同样会将非持久的数据落盘,并且删除消息内容,如果索引和消息是分开存储的情况下。也就是消息体大于 配置参数:queue_index_embed_msgs_below
2.2 将Q4里的 Quota - len(Q1) 条消息转移到Q3
由于==Q1总条数可能都不足Quota 条。所以有可能需要要由Q4分担一点==。
这里可能会有人会问,==在上面我们我们不是Q4转移到了Q3了,为什么这里可能需要再转一次==?
这里由于内存监控里,可能内存越来越少,算出来的每个队列最大可持续条数越来越少等情况。所以可能需要这一步操作
3. 将Q2或者Q3的一部分数据刷到磁盘
上面操作只是将Q1,Q4的数据转移到Q2和Q3里。
虽然那些和索引分开存储的数据从内存中清除了,但那些索引数据还是占用内存的。
在一定条件下,所以还是要将一部分索引数据也从内存中移除。
比如数据一直在写入,但是消费速度完全跟不上。
那就得把队列中间那一部分数据无全刷到磁盘,在消费的时候,再从磁盘中慢慢读取出来。
这样保证了==消费和写入的性能,不会立马下降==。
每次要刷多少条索引数据到磁盘,根据以下算法
%% 拿到当前队列允许的beta类型的消息上限
permitted_beta_count(#vqstate { len = 0 }) ->
infinity;
permitted_beta_count(#vqstate { target_ram_count = 0, q3 = Q3 }) ->
%% rabbit_queue_index:next_segment_boundary(0)拿到0对应的磁盘文件的下一个磁盘文件的第一个SeqId
lists:min([?QUEUE:len(Q3), rabbit_queue_index:next_segment_boundary(0)]);
permitted_beta_count(#vqstate { q1 = Q1,
q4 = Q4,
target_ram_count = TargetRamCount,
len = Len }) ->
BetaDelta = Len - ?QUEUE:len(Q1) - ?QUEUE:len(Q4),
lists:max([rabbit_queue_index:next_segment_boundary(0),
BetaDelta - ((BetaDelta * BetaDelta) div
(BetaDelta + TargetRamCount))]).
%% 当前beta类型的消息大于允许的beta消息的最大值,则将beta类型多余的消息转化为deltas类型的消息
case chunk_size(?QUEUE:len(Q2) + ?QUEUE:len(Q3),
permitted_beta_count(State1)) of
S2 when S2 >= ?IO_BATCH_SIZE ->
%% There is an implicit(含蓄), but subtle(微妙), upper bound here. We
%% may shuffle a lot of messages from Q2/3 into delta, but
%% the number of these that require any disk operation,
%% namely index writing, i.e. messages that are genuine
%% betas and not gammas, is bounded by the credit_flow
%% limiting of the alpha->beta conversion above.
%% 将S2个betas类型的消息转化为deltas类型的消息
push_betas_to_deltas(S2, State1);
_ ->
State1
end.
==根据 消息总量 ,只有索引在内存数据不在内存(beta状态)的消息总量 ,以及 最大可存内存的总 数 算出一个值 ,再与Q2,Q3 的总和对比,算出值S2. 如果这个差值S2 >= 2048 的时候,进行将 S2 条消息索引刷到磁盘。==
BetaDelta 肯定是 >= len(Q2)+len(Q3)的,Q2,Q3只是一部分数据索引在内存数据在磁盘的索引数据
==TargetRamCount 大不是代表内存可能还比较充足么,为什么反而还要刷更多盘?==
这是由于TargetRamCount 的值队列平均持续时间 * 速率之和。
并且 TargetRamCount 都产生值了的情况下,意味着erlang虚拟机内存占比超过一定比例了,所以需要将更多的数据刷到磁盘。以保障后面内存更快的释放出来。
==在内存不够的情况下,也将最少刷 16384 条消息到磁盘==。
如果Q2,Q3的消息总和超过16384的情况下。因为一个索引文件最多存16384条索引信息,所以这里同时还考滤了一次性往一个索引写入16384条消息,考滤了磁盘的顺序IO问题。
1). 优先将Q3里的索引信息刷到磁盘,保留 Q3里的最早的那个索引不刷盘。
2). 再将Q2里索引信息刷盘
3). 索引刷盘条数最多只刷 上面算出来的 S2 条。
4). 索引刷盘完成的时候,这条消息索引将从内存中删除,并且将最大ReqId和最小ReqId保存起来,放在deltas 变量里
4. 数据消费
4.1 优先从Q4里消费数据
4.2 假如Q4里没有数据了,那就再从Q3里消费数据
1). 假如Q3里没有数据,则认为没有数据
2). 因为Q3里最开始是从Q4里转移过去的,并且Q3里的数据刷盘的时候,第一条数据是绝不刷盘的。这里保证了数据顺序性。如果从Q3里读取出一条数据,如果Q3为空了,则从磁盘中加载数据